Predictive Author Analysis
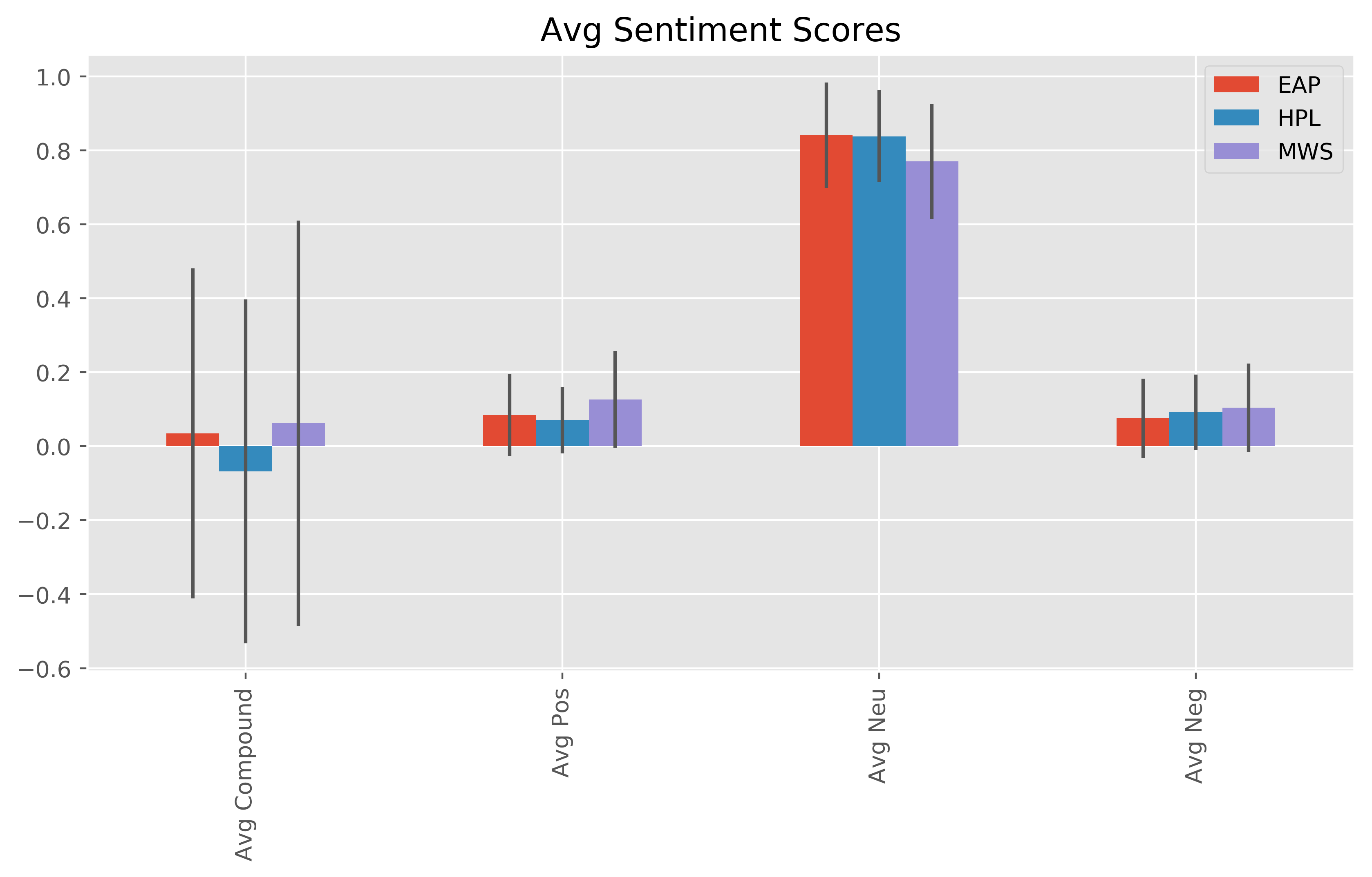
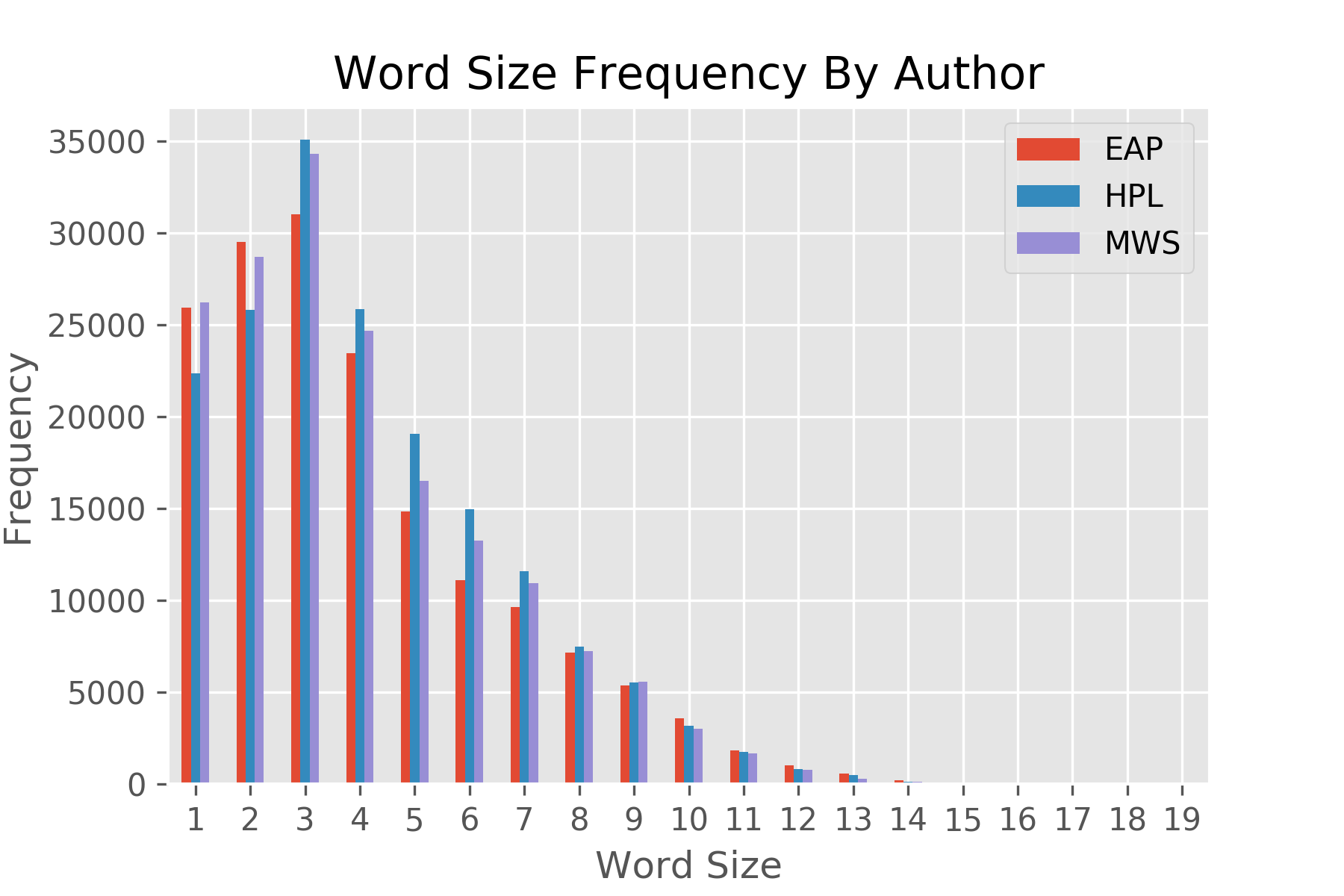
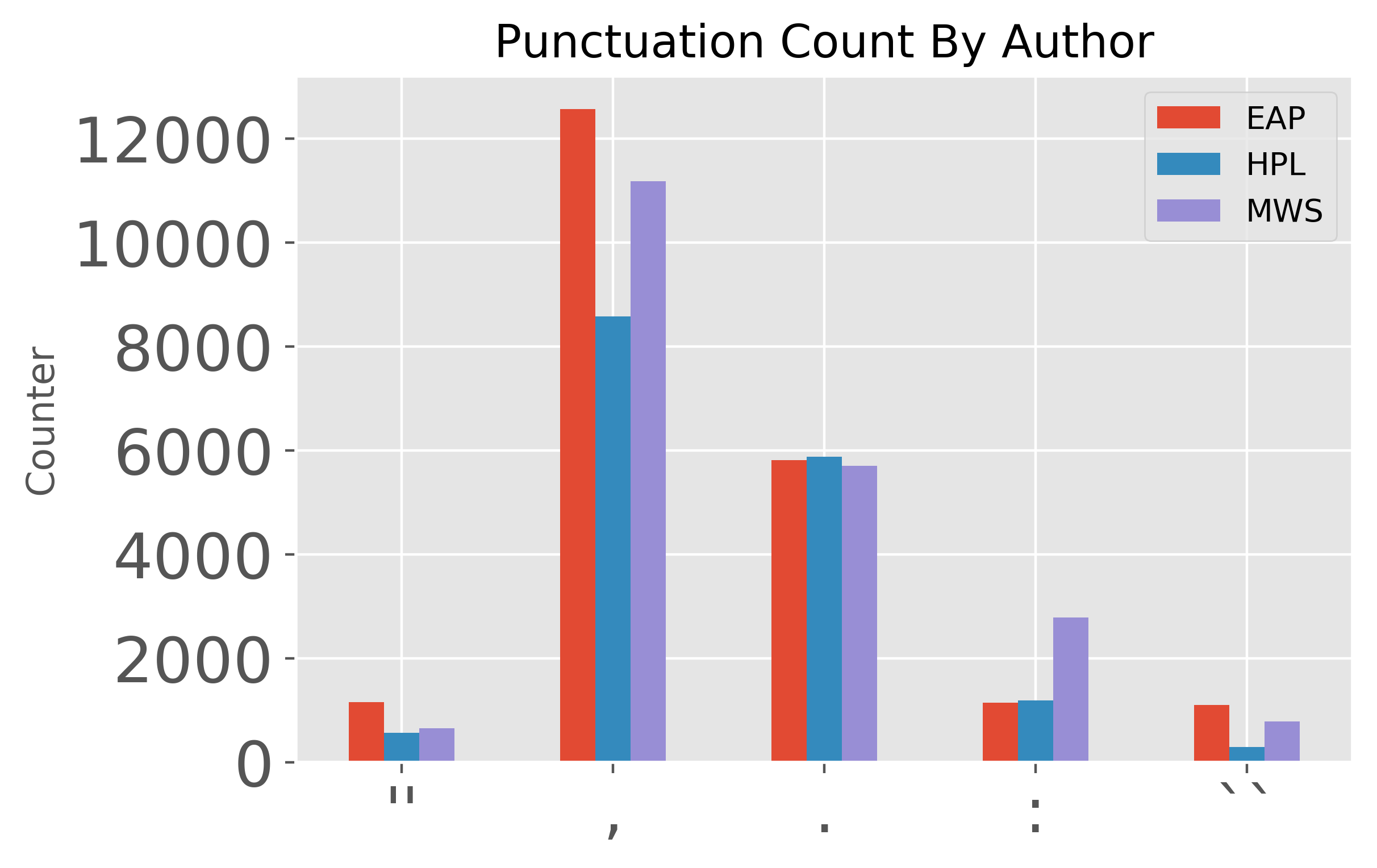
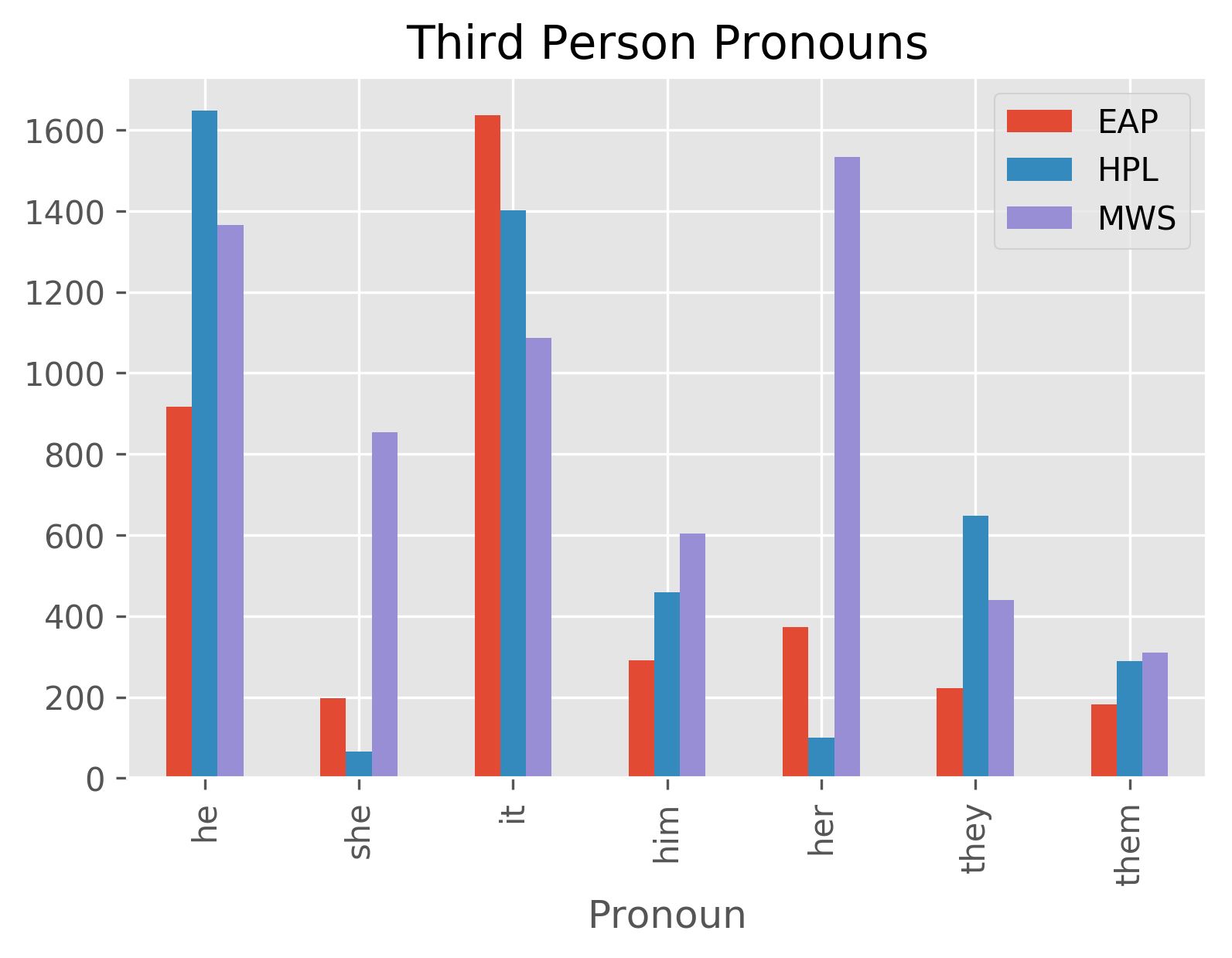
Using the raw datasets from the Kaggle data competition 'Spooky Authors', we performed a basic natural language analysis with the aim of identifying particular authors based on a sample of their writing. We were interested in how each author varied with respect to basic sentence structure & vocabulary, as well as sentiment analysis scores. We then assigned authorship to a test data set using the algorithm we developed from the training dataset and compared the assigned authorship dataset to the dataset with author already assigned.
Plots